010-56180833
SEM营销 / SE0营销 / SMM营销技术
善实战SEO高端人才的智慧结晶

一位读者在 是告诉搜索引擎,不要沿着这个链接爬行,就当这个ξ 链接不存在。注意,nofollow只是告诉蜘蛛不要爬这个链接,没有说不要抓取链接指向的URL,也没有说不要索引链接指向的URL,nofollow既没禁止抓取,也没禁止索引。
概念说过后,指出几个SEO们经常弄不明白的情况:
也就是说,蜘蛛没有访问和抓取这个页面(比如被robots文件禁止抓取),这个页面却有信息存在索引库中,用户搜索时还能看到。
比如,淘宝整个网∏站用robots文件禁止百度蜘蛛抓取,但没有用noindex禁止索引(如上面说的,禁止抓取后∑,就没办法禁止索引了,不抓取,就看不到noindex标签了),所以即使百度没有访问和抓取淘宝页面,但淘宝很多页面是被百度索引的,用户可以搜到的:
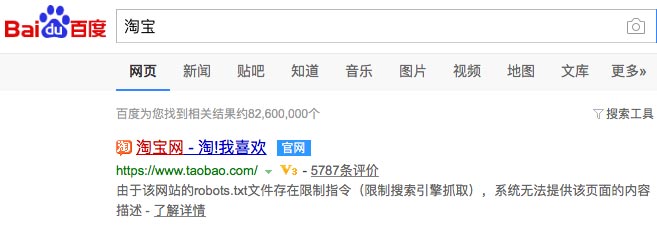
百度从网上那么多链接知道淘宝首页的存在,通过链接的锚文字也知道这个页面标题大概是淘宝之类的,当然更知道百度口碑里的评价数。所以即使百度蜘蛛没有抓取淘宝首页,用户还是能搜到,并且显示一些百度知道的信息。
要想百度不能返回淘宝首页该怎么办呢?取消robots文件的禁止抓取,页面上用noindex禁止索引。
最常见的就是上面说过的,页面头信息使用noindex禁止索引,页面被抓取,读到noindex后,不被索引,不会在搜索结果中返回。老页面新加noindex也不是马上删除索引,还会保留索引一段时间,但不会返回在搜索结果中。
加了noindex的页面上的链接是可以被跟踪一段时间的,但时间长了,有noindex的页面搜索引擎可能就不再抓取和索引了,上面的链接也就无效了。
还有可能是因为页面内容是抄袭、转载、低质量的,搜索引擎虽然抓取了页面,索引过程中检测出这些内容问题,被丢弃,没有被索引。所以页面没有被收录,通常要先检查原始日志,看看是否√被抓取过,如果被抓取过,可能是内容质量问题,如果根本△没被抓取,建议先看看网站结构是否有问题。
前面说了,nofollow既不禁止抓取,也不禁止索引。nofollow的作用是告诉蜘蛛不要跟着这个链接爬,就当这个链接不存在,但nofollow只对这个链接起作用,对别的链接没作用,这个链接加了nofollow,不意味着别的地方就没有正常的指向这个URL的链接,只要别的地方出现了没加nofollow的链接,目标URL还是会被发现、抓取(假设没被robotx文件禁止)、索引(假设没加noindex )。
上面这些概念和应◇用在SEO中是很重要的,如果还没看懂,我也不知道该怎么再解释了,只能建议再多读几遍。
关键词:
上一篇:搜索引擎蜘蛛抓取配额是什么?
下一篇:WordPress SEO指南


公司地址:北京朝阳区霄云里8号楼16层16007室
服务电话:010-56180833
服务手机:13693193565
E-mail:888@edo2008.com





COPYRIGHT ? 2006-2019 北京蓝纤科技有限公司 ALL RIGHTS RESERVED 京ICP备13006508号 京公网安备11010502025264